
Mani Doraisamy
Developer forever
| FR
At Guesswork, we are a team of four engineers with no background in sales or marketing. So, we had to figure out a way to get customers without relying on any of those skills. That led us, through trial and error, to a surprising approach: we call it "Build a Cannon to Kill a Mosquito." Using this methodology, we’ve acquired over 4,500 customers. In my talk at Lean culture, I explained how we did it, and why this counterintuitive strategy works especially well for technical founders. This is a summary of that talk.
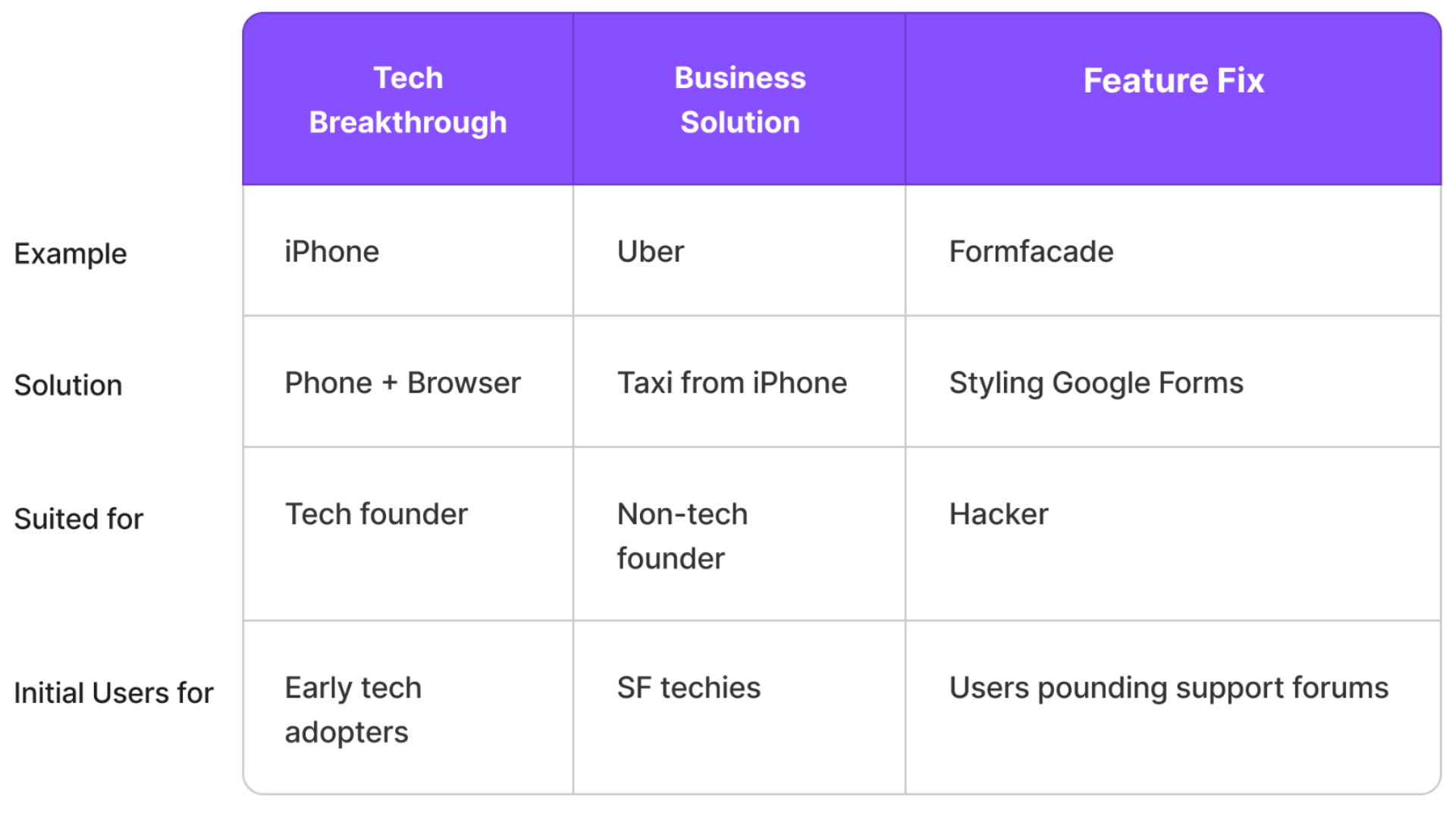
Three Startup Archetypes
Most startups fall into one of two categories:
Technology breakthroughs like OpenAI and the iPhone push the boundaries of what’s possible. They're hard to build, but once they work, adoption comes in waves.
Business model innovations like Uber apply technology breakthroughs (iPhone) to real-world problems (Taxi booking). They often start with niche users and expand from there.
But there’s a third type: solving a small, overlooked problem in a popular product—a missing feature users are desperate for. Take beautifying Google Forms. For Google, it’s a mosquito not worth swatting. For a third-party developer, solving it means recreating Google Forms’ interface—something you can’t do through standard APIs. It takes enormous effort—like building a cannon to kill that mosquito. But sometimes, that cannon uncovers gold. In our case, it helped us build three successful products.
Our Accidental Discovery
While launching products, I needed a lead form for our website. Google Forms had everything—easy setup, Google Sheets integration—but embedded on our site, it looked like a patchwork. So I restyled it with CSS to match our branding. That CSS hack became Formfacade. What started as a weekend hack turned into thousands of support requests from companies with the same frustration: they needed professional-looking forms that still synced to Google Sheets.
This taught us the mosquito principle: problems too small for big companies to solve, but painful enough that users will pay to make them disappear. The effort required feels disproportionate—rebuilding Google Forms just to change how it looks. But that's exactly why the opportunity exists.
Turning Accident into Playbook
Our second product emerged from Formfacade users. Doctors loved our forms but worried about HIPAA compliance. We studied healthcare regulations and built Hipaache with features like e-signatures, field masking, and intake forms.
But Hipaache didn’t sell on its own. It needed a salesperson to explain its value to doctors. When we split its features into separate add-ons, the signature add-on exploded. We renamed it Formesign and gradually bundled other features back in, creating a DocuSign alternative that lived inside Google Forms.
This became our systematic approach: find tiny problems competitors ignore, then use all your engineering skills to solve them—even if it means building a DocuSign inside an add-on.
Branding Problem with Add-ons
There is one big problem with this approach: churn. Customers treat add-ons as temporary solutions until Google builds it or migrate to a dedicated solution. During COVID, restaurants used Google Forms to take online orders but couldn’t calculate totals or manage inventory. We built those features and launched an add-on called Neartail. Businesses loved it and left 5-star reviews, but still switched to Shopify when they grew.
So we pivoted Neartail toward meal prep businesses — a niche that Shopify couldn’t serve well — especially when the menus change every week. We built a custom solution for weekly changing menus and redesigned our entire site around this audience. Today, over 50% of our traffic bypasses Google's marketplace entirely.
This transition required building two products simultaneously: one to solve order amount calculation in Google Forms, another to solve weekly changing menus for meal prep businesses. It’s harder than the traditional business solution archetype, where a founder could have directly built a "Shopify for meal prep," but a technical founding team like ours wouldn’t have known this segment existed without starting with the add-on.
The Two Tests
Every good mosquito problem passes two tests:
It makes you question your life choices. The problem feels beneath you. We went from building AI to styling Google Forms. That embarrassment is exactly why the opportunity existed—nobody else wanted to do it.
It should feel slightly impossible. If standard APIs could solve it, everyone would. Our best ideas involve unconventional approaches that feel like they shouldn’t work—but when they do, users experience magic.
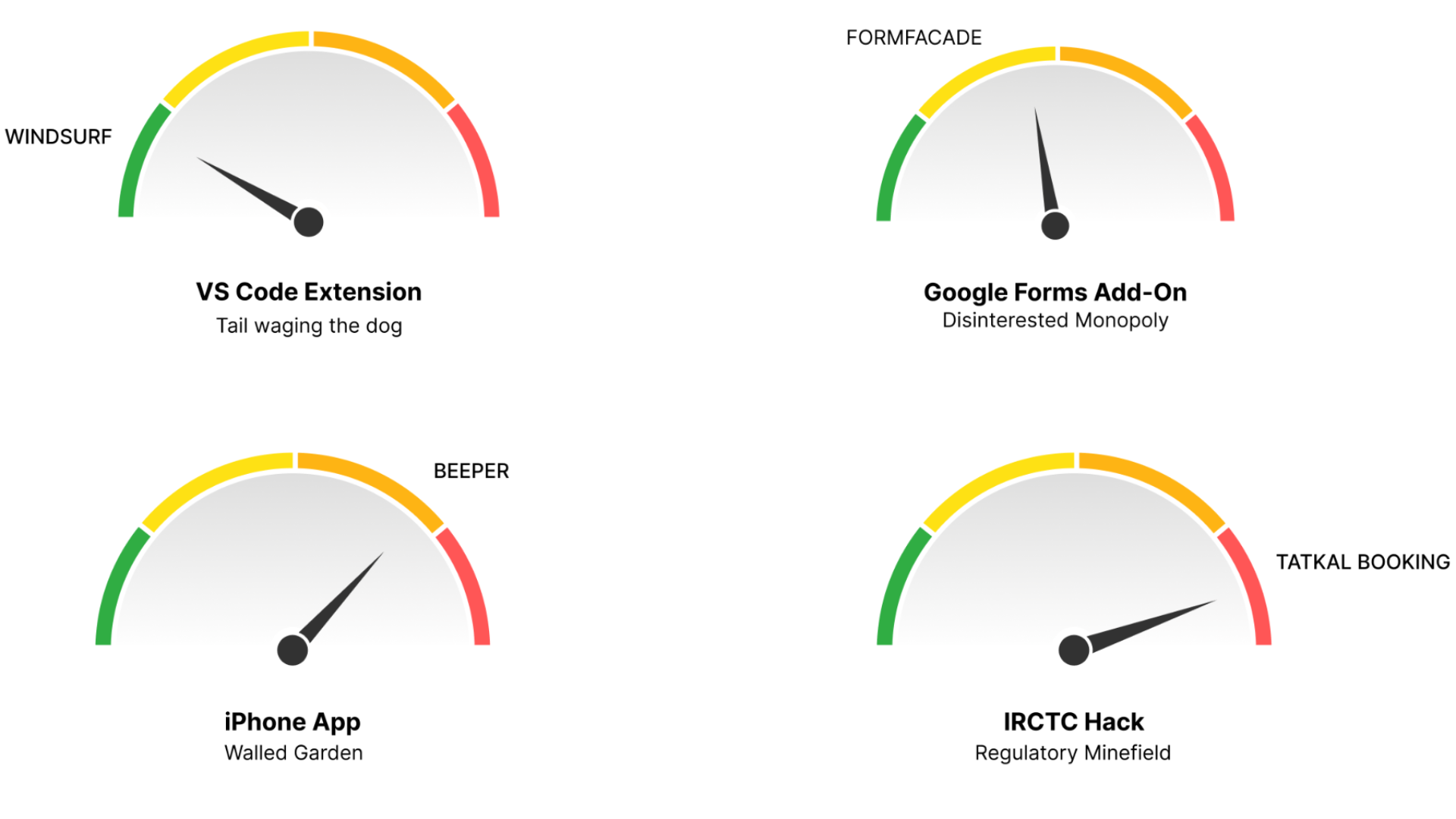
The Spectrum of Risk
Not all platform extensions are equal. Here’s the risk spectrum:
Tail Wagging the Dog: Windsurf started as a VS Code plugin but hit platform limits around AI autocomplete. They forked the entire editor, rebuilt the experience, and forced Microsoft to opensource its vscode & copilot. When your momentum becomes large enough, you can actually reshape the platform.
Disinterested Monopoly: Google Workspace is built for office productivity. It prioritizes co-worker use cases over customer-facing use cases. Their forums overflow with unanswered requests. Great for building on top of, if you're willing to work around missing APIs.
Walled Gardens: Apple and Meta guard their platforms aggressively. When Beeper enabled blue bubble messages from Android, Apple shut it down immediately. Despite EU regulations like the Digital Markets Act, these remain high-risk environments for third-party products.
Regulatory Minefields: Government platforms offer massive user frustration but dangerous legal territory. A student in India was jailed for building a better train booking site. The regulatory risk increases significantly as you move east—from the U.S. to Europe to India to China.
Start with disinterested monopolies. If your wave gains momentum, you might become the tail that wags the dog.
Summary
One way to think about this approach is to understate your product when everyone else overstates theirs. Most founders want to be visionaries—like Elon Musk, the real-world Iron Man. But maybe the better strategy is to start as a sidekick. That’s what PayPal did. They were a payment plug-in for eBay. When eBay felt threatened, they tried to compete, failed, and eventually acquired PayPal with a mix of carrot (acquisition offer) and stick (threat to shut them down). But Elon used that money to build Tesla and SpaceX.
While add-ons seem too insignificant and unimpressive, they are an underrated lever behind success stories like PayPal and Windsurf. This approach will become more valuable as AI makes software development cheaper. When any SaaS can be cloned overnight, your greatest leverage becomes distribution. As Nikita Bier observed:
"The entire tech community thinks AI coding will shift power from engineers to idea people. Wrong—it flows to whatever maintains scarcity: those who understand distribution."
As someone who uses AI for everything, I decided to take it a step further and asked ChatGPT to do my performance appraisal. It was surprisingly good. For example, it knew my coding style (my preference for promise instead of async/await) and recommended me to document it for onboarding new employees. No human manager would’ve been this precise. In a few years, AI may understand all our preferences and evolution better than we do. ChatGPT’s implementation of memory allows it to learn from prior conversations, enabling this kind of personal modeling. And that led me to wonder: what if ChatGPT could share just this performance summary with other tools (like peer review systems or mentoring platforms) without exposing everything else it knows about me? It turns out, that’s exactly what OpenAI is building towards. Sam Altman explained in his talk yesterday:
“Young people don’t really make life decisions without asking ChatGPT... it has the full context on every person in their life... the memory thing has been a real change.”
“You should be able to sign in with ChatGPT to other services. Other services should have an incredible SDK to take over the ChatGPT UI... You’ll want to be able to use that in a lot of places.”
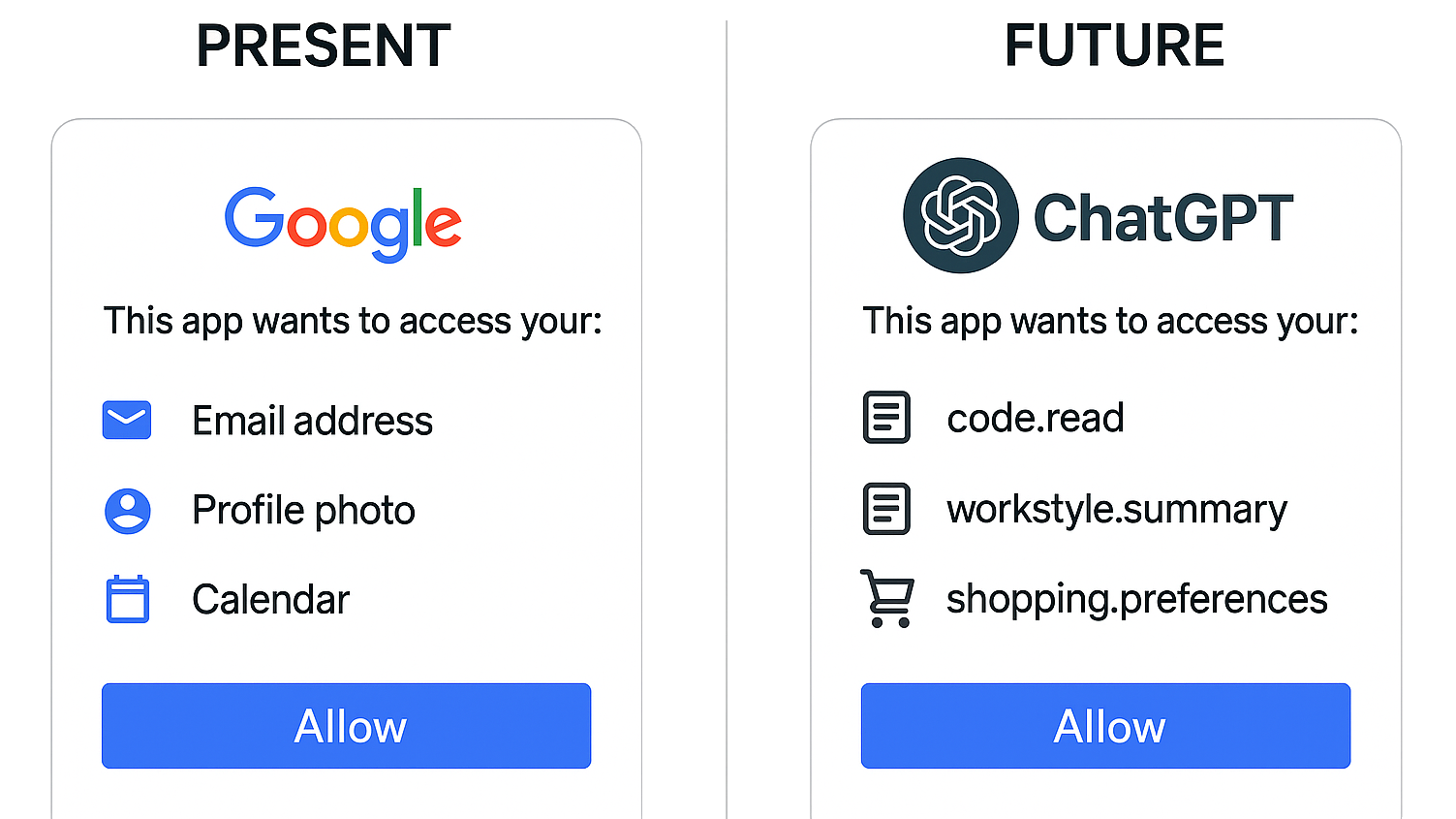
Scoped AI Memory Access
- scope:code.read — might allow access to your coding history for developer tools.
- scope:workstyle.summary — might share a personal performance snapshot for review systems.
- scope:shopping.preferences — might let e-commerce platforms tailor recommendations to your taste.
What This Means for Developers
- Your app becomes a node in the user's AI graph: Skip onboarding flows and just tap into scoped AI memory.
- Fine-grained access that users can trust: Users will expect precision access - apps that read only what they need.
- Standardization will open doors: If OpenAI defines an OAuth-like memory scope system, it creates a platform for trusted plugins, apps, and agents.
One of the constant debates I have with my dad is how unhealthy fruit juice is compared to whole fruit. Bottled juices from supermarkets often strip away fiber and vitamins, leaving mostly sugar. Even when these drinks are fortified with vitamins and labeled to resemble real fruit, they’re nowhere near as healthy. That’s why NutriScore - an algorithm designed to rate food healthiness doesn’t just analyze ingredients; it begins by determining the category of the food. Fruit juice and whole fruit are scored differently.
This classification step is at the heart of Neartail’s search engine for healthy food. Our system uses a series of fine-tuned AI agents to compute NutriScore and rank food items accordingly. Here's how our workflow is structured:
Ingredient Extraction Agent: Scrapes nutritional data (sugar, fat, fiber, etc.) from product webpages.
Estimation Agent: Fills in missing values using probabilistic guesses based on similar products.
Classification Agent: Categorizes the food item (e.g., General Food, Red Meat, Beverage, Cheese).
Scoring Agent: Applies NutriScore calculation tailored to the classified category.
It sounds simple, but we quickly encountered what we call the butterfly effect - a phenomenon where small upstream mistakes trigger large, downstream consequences.
Why the Butterfly Effect Happens
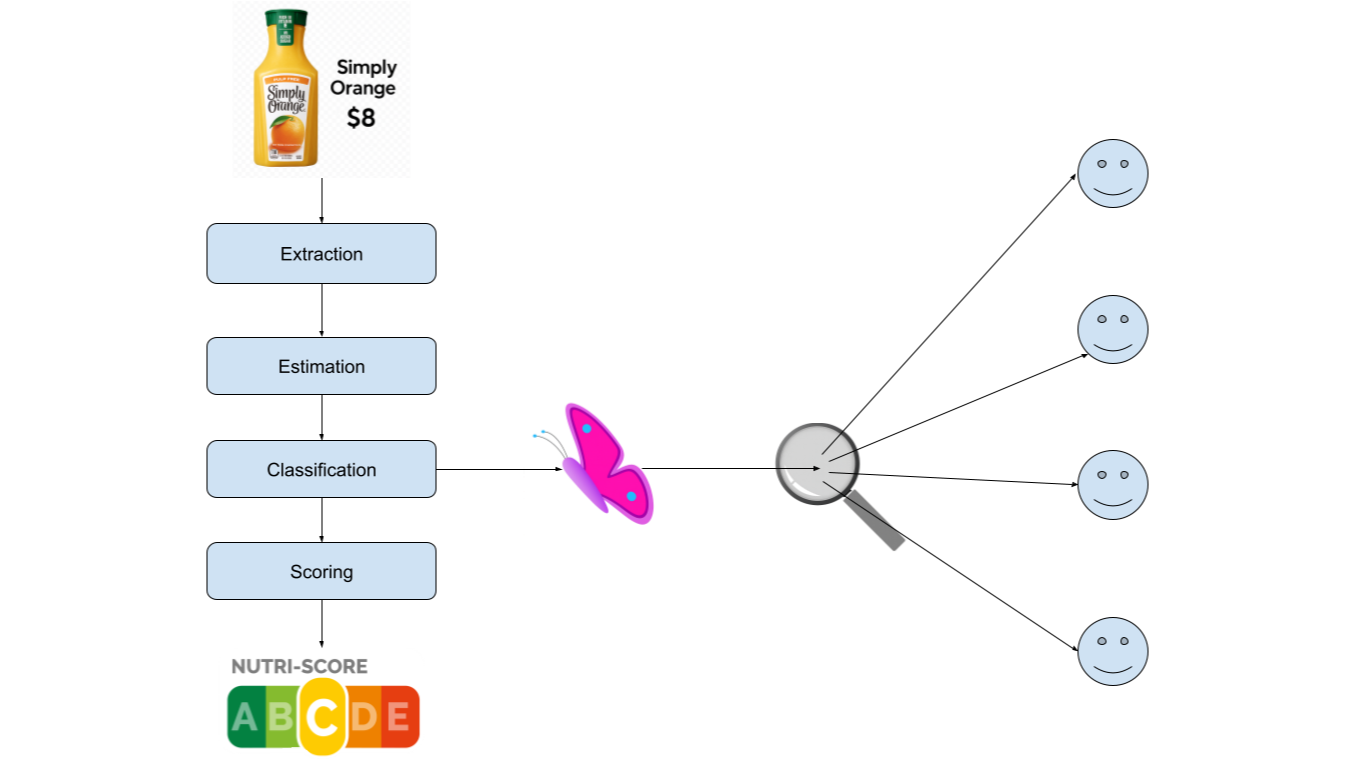
- Misclassification in a Critical Step:
In agentic workflows, errors in critical steps - what we call "butterfly steps" - can change the entire outcome. For example, if our system misclassifies a fruit juice as a general food rather than a beverage, the scoring becomes lenient. Since beverages are penalized more harshly for sugar, the misclassification leads to an inflated health score. The result? An unhealthy product appears healthy. - Amplification Through Repetition:
The second cause is repetition. Consumer workflows (e.g., trip planning) are often one-off. Prosumer workflows (e.g., generating leads) may be repeated occasionally. But B2B workflows - like extracting financial data from quarterly reports - run daily. A small classification bug in these scenarios can corrupt thousands of records or mislead entire business dashboards.
How We Contain the Butterfly Effect
We use multiple guardrails to keep these errors in check:
Finetuning for Butterfly Steps (using Promptrepo): For high-risk steps like food classification, we rely on finetuned models rather than prompting. We also enforce strict output schemas - like predefined enums for food categories.
Field-Level Confidence Scoring (using @promptrepo/score): We convert logprobs into 0 - 1 confidence scores. For example, if the system is only 0.62 confident that coconut water is a beverage, we flag it for review.
Human-in-the-Loop Review: Low-confidence values are escalated to business owners for manual review. Their corrections feed back into the system, continuously improving reliability.
These layers help us build agentic systems that are not only intelligent but trustworthy. And this isn't limited to food classification. Whether it’s healthcare, finance, or legal tech, systems that rely on early classification are prone to similar ripple effects. Left unchecked, small errors can scale rapidly. Guardrails are not optional - they're essential.
The Future of Agentic Workflows
Agents will evolve based on how frequently they are used and how critical their outcomes are. Consumer agents like Manus and Deep research will prioritize usability, with a simple confirmation of steps before executing them. Prosumer agents will blend flexibility and ease of use through a no-code UI to edit steps. Enterprise agents will demand full customization and fine-tuning of each workflow step.
User Type | Past | Future | Workflow steps | Butterfly Step |
|---|---|---|---|---|
Consumer | Google + Human | Agentic Bot (Manus) | Confirm | - |
Prosumer | No-code Tool | Config-based Agent + UI (Google ADK) | Edit | Prompting |
Business | SaaS | Code-based Agent (MCP + vibe code) | Create | Finetuning |
1. Manus-like, Synthesized agents for consumers
Workflows are synthesized automatically.
Internals are opaque, but chain-of-thought reasoning provides some transparency.
Ideal for lightweight, one-time decisions where usability matters most.
2. Config-Based, No-Code agents for prosumers
Users define workflows visually through configuration.
Balances ease of use with the ability to review and modify the workflow.
Ideal for moderate-frequency use cases with some business risk.
3. Domain-Tuned, Code-Based agents for businesses
Developers write and orchestrate workflows in code.
Precision and fine-tuning are essential.
Suited for high-frequency, high-stakes applications that demand auditability.
Summary
"AI is the most significant change in programming. For the first time, logic is transitioning from deterministic to probabilistic."
I tweeted this nine years ago, expecting two big changes:
Probabilistic algorithms - like classification and extraction - would be embedded into everyday code, just like deterministic algorithms such as sorting.
But we'd treat them differently: always checking confidence levels and involving humans when uncertainty arises.
The first change happened. The second didn’t. Today, we use probabilistic algorithms in deterministic code, deploying them to thousands of users without understanding how confident the system is in its outputs.
Would you convict a person if there were a 75% chance he was guilty? And yet, we take similar chances in AI workflows every day. As we move from AI as an assistant to AI as a decision-maker, we must identify the butterfly steps - finetune them, check confidence scores, and ask whether a human should weigh in. Otherwise, we risk the other prediction I made:
"AI takeover won't be like Skynet, but it might still have the same effect. It'll start with small improvements to UX by suggesting what user wants. But as accuracy increases, users will get hooked & delegate all decision making to AI."
AI’s Intuition Without Proof
LLMs are a lossy compression of the internet.
— Andrej Karpathy
- In the long term, AI companies are likely to build interpretable (explainable) AI that explains its reasoning through deductive steps, similar to math steps or programming code, making its derivations transparent. Neurosymbolic AI could generate deterministic code or rules that humans can review and execute consistently, unlike LLMs that produce different answers for different users.
- In the short term, we need human reasoners who validate AI-generated insights, much like Hardy did for Ramanujan. They can analyze AI’s solutions, refine its ideas, and prove its intuition with deductive reasoning. Even in the long term, we might still need reasoners to peer review scientific discoveries made by interpretable AI, to ensure that AI’s intuition is grounded in deduction—especially in critical areas like cancer research, defence and nuclear fission. Human reasoners will remain essential for safe AI alignment and to prevent hallucination in high-stakes domains.
Impact on the Labor Market
- Blue-collar jobs — e.g. users who operate software to complete their work.
- White-collar jobs — e.g. engineers who build that software for users.
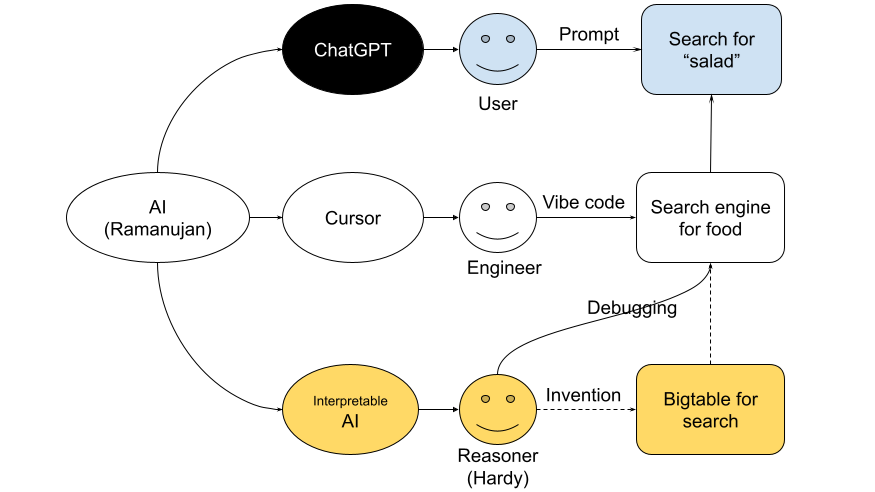
- As a user: I asked ChatGPT to find a healthy "protein salad" I could buy in San Francisco and to rank them by NutriScore. It found relevant salads, but made up the NutriScores: the first salad was rated “A” (healthy), the second “B,” and the third “C” (not so healthy)—without showing how these scores were derived. It was like a school student writing answers in an exam without showing the steps. So, I had to act like a teacher, explaining how to calculate the NutriScore.
- As an engineer: I wanted to build a search engine for healthy food instead of explaining NutriScore calculation to ChatGPT every time. But when I tried to vibe-code it using Cursor, it failed to classify the food correctly. NutriScore is calculated differently for each food category, such as vegetables vs. meat. This required an AI pipeline: first, classify the food; then extract nutrient data from the webpage; if nutrients are missing, generate them based on the ingredients; and finally, calculate the score based on category and nutrients.
- As a reasoner: A vibe coder can build a CRUD app today. But building or debugging an AI pipeline requires deeper understanding. For Neartail’s food search, we needed reasoners, not just vibe coders. This doesn’t stop with applications—Google started as a search engine, but to index the web, they built Bigtable, challenged the CAP theorem, and created Firestore, which we now use as a simple JavaScript library. That's how we ended up creating our own finetuning tool to build AI models like the NutriScore calculator.
Summary
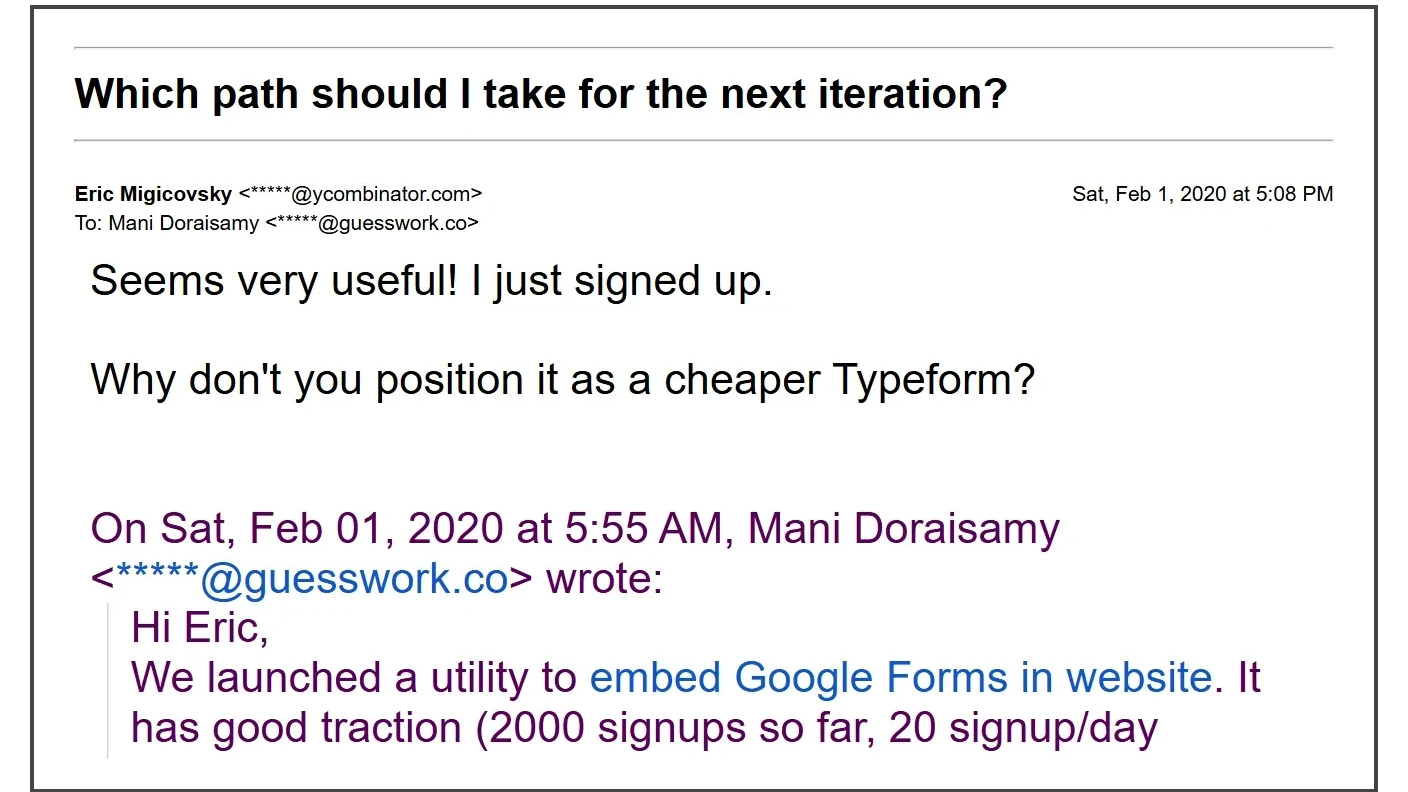
I was in touch with Eric Migicovsky, a YC partner who had provided feedback on my startup. His feedback encouraged me to pursue what most people considered an add-on rather than a serious product. It quickly grew to over 1,000 paying customers, but our churn was high. I applied to YC, hoping to get their advice on solving churn rather than continuing to pester Eric. But with surgery looming, I reached out to him and asked if I should inform YC about my condition. He advised me not to worry about it now and to tell them after the interview. That only made me more anxious. Despite our best efforts, we were rejected due to the high churn and dependence on Google. I was disappointed, but I had bigger concerns—namely, the surgery and ensuring someone could manage the product in my absence.
Impact on Our Startup
Impact on My Life
- Avoid inflammatory foods like sugar and unhealthy fats (saturated and trans fats), which narrow blood vessels and increase the heart’s workload.
- Engage in moderate exercise that strengthens the muscles without aggravating the leak. Excessive exertion could rupture the valve, leading to further dilation and heart failure.
Impact on Our Product
- We transitioned Neartail from a generic eCommerce product into a solution for food businesses that serve healthy food. Now, we building a search engine to find healthy food.
- We repositioned Formesign from a generic eSignature tool into a healthcare compliance tool that simplifies patient admission in hospitals.
Lessons I Learned
- I used to dismiss the "hit by a bus" scenario as a boogeyman for large, inefficient teams. But as I get older, I realize the inevitability of health crises and the possibility of death. While I no longer dismiss the risks, I also don’t want to give up on my dream of "staying small and scaling big" out of fear. We can acknowledge our fears and still keep our dreams afloat.
- Many founders start with a mission—a problem they believe is worthy enough to dedicate their lives to solving. My journey was the reverse. I built the products first and discovered my mission later. So, if you haven’t found your life’s purpose yet, there’s still time to find one.
- Going through this experience was terrifying at the time, and I still go for checkups every year to ensure my heart doesn’t dilate beyond acceptable limit. But these days, it feels like a victory lap—a proof that my fitness regimen is working and that I have been able to overcome a scary period in my life.
Using Google Forms as a CRM
- Demo Scheduling: Prospective customers fill out a form to book a demo, and the data flows directly into our CRM system (built on Google Forms and Sheets).
- Support Requests: When users submit a bug or feature request, it’s automatically emailed to us and logged in our support forum. We also use an AI-powered auto-composer that suggests responses based on similar past questions.
- Subscription Management: When a user subscribes to a paid plan, we ask if they’d like to schedule a setup call. If they cancel, we collect feedback to understand why. Both use Google Forms as well.
Evolution of CRMs
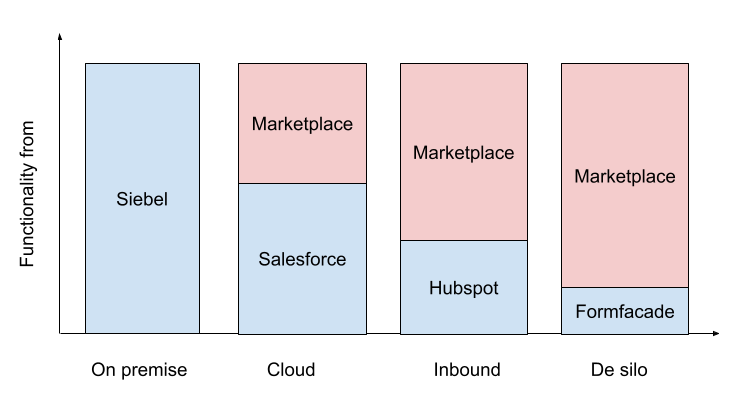
- Salesforce was built for sales teams tracking leads in spreadsheets but losing them when employees left. It moved sales tracking to the cloud.
- HubSpot focused on inbound leads, capitalizing on the rise of freemium SaaS models.
- Formfacade isn’t trying to be HubSpot or Salesforce. We’re focused on turning Google Forms into a lightweight CRM—one that meets SMBs where they already work: Google Workspace.
- Siebel era: Customer interactions weren’t online, and neither were their records.
- Salesforce era: Interactions were still offline, but records moved to the cloud.
- HubSpot era: Both interactions and records went online as inbound leads became mainstream.
- Formfacade: With Google Workspace so pervasive, businesses don’t need a full-fledged CRM like HubSpot.
Habit-Forming Leads to Silos
When elevators are running really well, people do not notice them. Our objective is to go unnoticed.
- Otis
One of our customers described how managing a single customer interaction required 10 different tabs, from email and calendar to HubSpot and payment software. We hear this repeatedly from our customers because, as builders, we aim to make our software an integral part of their workflow and turn it into a habit for retention. But this increases silos and complicates the workflow for customers. This complexity is precisely why Klarna recently moved away from Salesforce to a custom-built CRM, consolidating everything into one AI-powered system.
With AI, we can now extract structured data from emails and conversations to build a CRM without manual intervention. Instead of requiring businesses to adopt an entirely new system, we can integrate seamlessly into their existing tools like Google Workspace. Today, every software is slapping a chatbot on top and calling it AI. But the true power of AI lies in extracting information from existing tools and making business software invisible. This approach may prove more effective than the latest fads (such as chatbots and agents) for startups looking to disrupt existing software across different business verticals. I hope these two lessons I learned in this journey:
- Something as small as adding CSS to Google Forms can lead to a viable product with traction.
- Piggybacking on existing tools like Google Forms can be less sticky but can attract customers who are tired of switching between silos.
Disappearing Pillars

Double Threat to Big Companies
- They must cut down their workforce, even if employees are highly skilled, creating a moral dilemma.
- They have to rebuild their products from scratch for the AI era - a challenge for elephants that can't dance.
Summary
AI takeover won't be like Skynet, but it might still have the same effect. It'll start with small improvements to UX by suggesting what user wants. But as accuracy increases, users will get hooked & delegate all decision making to AI.

The Problem with Vibe Coding
- No understanding – You don't know how the code works, only the requirements you wrote in English. When something breaks, you're stuck debugging AI's work instead of your own, which often becomes more time-consuming than writing your own code from scratch.
- No learning – If you never engage with code, what’s the difference between you and the end user? Why can’t the end user cut out the middleman (you) and do it themselves?
Start with a Brittle Toy
- He can still understand his game’s logic because he started with something he built himself.
- He can learn better coding practices by seeing how AI translates Scratch logic into C# logic.
- He stays in control of the development, rather than outsourcing the thinking to AI.
Grow it into a Dragon
Summary


- Analytical AI that will thrive without human feedback (like Deepseek R1 Zero).
- Creative AI that relies on human feedback for understanding human ambiguity (like ChatGPT-4).

How R1 Zero Achieves Deterministic Reasoning
- Reinforcement Learning with Binary Rewards:
R1 Zero trains on tasks where outputs are either correct or incorrect, like solving math problems or determining the best chess moves to win a game. This allows the system to refine its reasoning iteratively without relying on expensive, human-labeled datasets. - Execution and Validation:
After generating a solution, R1 Zero executes it (e.g., running a program or applying a formula) to confirm its correctness. This ensures repeatable, deterministic outputs—a stark contrast to the variability of LLMs. - Narrow Focus:
R1 Zero excels in structured tasks like coding or financial modeling by avoiding ambiguous, subjective problems. Its narrow specialization enables higher accuracy and efficiency.
Why R1 Zero Matters More Than R1
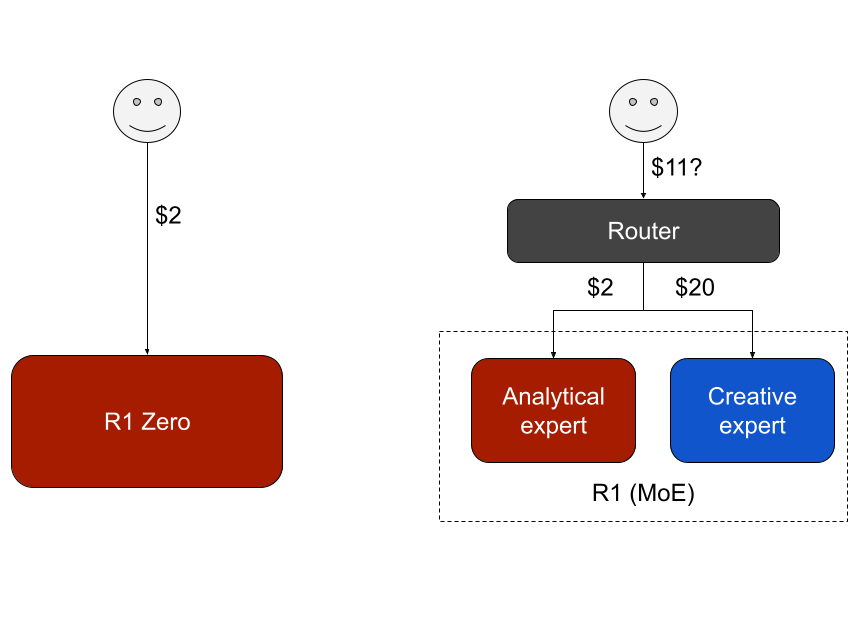
- Analytical Intelligence Will Be a Cottage Industry:
By avoiding reliance on costly data labeling or human feedback, R1 Zero allows smaller companies to build low-cost, deterministic AI systems. Startups can now create AI for niche tasks like coding or math because they don’t need to hire people to clean up the data for training. They can run reinforcement learning, which only requires compute costs instead of people costs. - Superintelligence Will Be Like a Ferrari:
While LLMs like GPT excel in creative and ambiguous tasks, R1 Zero specializes in precision and logic. Together, they could form a 'mixture of experts' (MoE), where analytical tasks would be routed to an AI model like R1 Zero, while creative tasks would be handled by a GPT-like AI model. This combination is what I call as the hybrid approach in my superintelligence article. This would be invaluable for high-end tasks like scientific invention, but doing both might be expensive. Analytical intelligence startups may have a pricing advantage here, forcing LLM providers to introduce token-based pricing specifically for analytical tasks. However, such a shift would complicate its pricing model. - Will Desktops Replace Mainframes?
Eventually, analytical intelligence like R1 Zero might become cheaper to build and deploy on low-end devices like desktops, robots, or phones. They may not even need to connect to multi-billion-dollar AI clusters. This is reminiscent of desktops taking over mainframes, as explained by Clayton Christensen in his book The Innovator’s Dilemma, where disruption happens when a cheaper product—like analytical intelligence—becomes increasingly capable, pushing super intelligence into niche applications and eventually making it less relevant.
- Analytical Intelligence: Deterministic reasoning for math, logic, and coding. (e.g., R1 Zero)
- Creative Intelligence: Generating ideas, designs, and narratives. (e.g., ChatGPT-4)
- Artistic Intelligence: Producing visuals, music, and other forms of artistic expression. (e.g., DALL-E)
Summary
This isn’t just a shift in how we think about AI—it’s a shift in how we value human skills. Analytical intelligence is coming, and it will reshape not just industries but our economy and our sense of purpose in a world where reasoning machines take over tasks we once prized most.

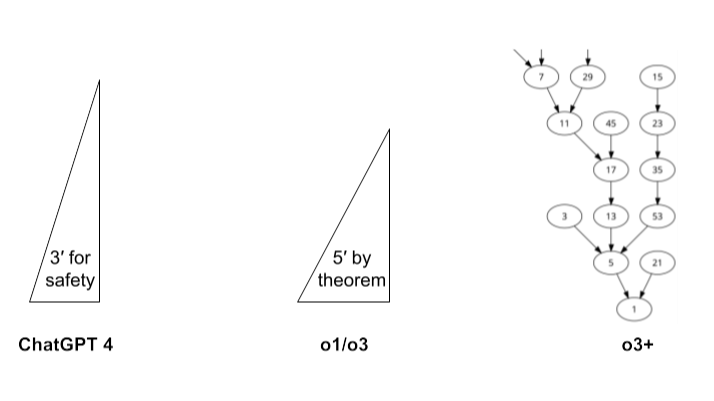
 The idea of moving up the metadata stack to become more intelligent isn’t new to developers. Workers use calculators (data tools) to solve specific problems like finding ladder distances. Developers abstract these tasks into code (metadata), using programming languages like python to automate such problems for millions of workers around the world. At the highest level, language creators build meta-tools like compilers that compile and execute code that helps millions of developers around the world. They use meta-metadata tools, like Python's PEG (Parsing Expression Grammar) or ANTLR (a parser generator) to create new programming languages and compilers.
The idea of moving up the metadata stack to become more intelligent isn’t new to developers. Workers use calculators (data tools) to solve specific problems like finding ladder distances. Developers abstract these tasks into code (metadata), using programming languages like python to automate such problems for millions of workers around the world. At the highest level, language creators build meta-tools like compilers that compile and execute code that helps millions of developers around the world. They use meta-metadata tools, like Python's PEG (Parsing Expression Grammar) or ANTLR (a parser generator) to create new programming languages and compilers.OpenAI's o3 launch yesterday made me question my identity as a developer. Seven months ago, I predicted that AI would soon add deterministic behavior to its probabilistic foundation. Still, I was shocked to see it happen in the same year. This model is no longer just a coherent word generator; it outperforms 99.8% of developers in competitive coding. Although OpenAI is tight-lipped about its implementation, they seem to have achieved this through program synthesis — the ability to generate algorithms on the fly just like how developers write code to solve problems. In this post, I explain how similar o3 thinking is to the way we think as developers and explore our relevance in this new AI era.
How Users Create Logic
Users think with data. Imagine you are a cashier at a grocery store. You learn how to calculate the amount by watching the owner do it for a couple of customers. Based on that, when a customer buys 10 carrots, you would find its price as $2 and multiply $2×10 and tell them that they have to pay $20. This is why users use spreadsheets for repetitive tasks. It provides an intuitive way for users to work with data while writing formulas that can be applied to consecutive rows and see the results immediately:
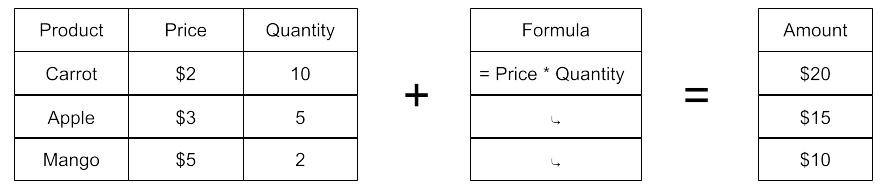 Developers, on the other hand, think with algebra (i.e., as metadata). They declare variables—such as Price and Quantity—multiply them, and assign the result to another variable, Amount. They have the ability to express this logic in an IDE without seeing any data. Only at runtime do they get to apply data and check if their logic is working correctly. This ability to abstract logic is what separates developers from users. This is what makes them build billing software that calculates order amounts millions of times for thousands of customers.
Developers, on the other hand, think with algebra (i.e., as metadata). They declare variables—such as Price and Quantity—multiply them, and assign the result to another variable, Amount. They have the ability to express this logic in an IDE without seeing any data. Only at runtime do they get to apply data and check if their logic is working correctly. This ability to abstract logic is what separates developers from users. This is what makes them build billing software that calculates order amounts millions of times for thousands of customers.
How Machine Learning Creates Logic
Machine learning works like users. Based on the examples, it finds the pattern using linear regression. It would learn that Amount = Price × Quantity based on that pattern. It’s like a student memorizing multiplication tables without understanding why multiplication works.
.png) Once it learns this pattern, it applies this logic to new inputs, just like a spreadsheet formula that is applied to consecutive rows.
Once it learns this pattern, it applies this logic to new inputs, just like a spreadsheet formula that is applied to consecutive rows.
How o3 Creates Logic on the Fly
With o3, AI no longer thinks like a user. It thinks like a developer. Just like a developer's brain can think about a problem and come up with a solution using code, o3 generates a program (i.e., metadata) on the fly to solve the problem. Once the program is created, it is executed like developer-written code, producing consistent outputs for the same inputs. The first part is called program synthesis, and the second part is called program execution.
.png) Program synthesis is like hearing a problem and coming up with a completely new spreadsheet and a bunch of formulas to solve that problem. It doesn’t need data to come up with formulas anymore. It can create a new algorithm that did not exist before and verify the correctness of the solution during program execution, much like how developers test and validate their code at runtime.
Program synthesis is like hearing a problem and coming up with a completely new spreadsheet and a bunch of formulas to solve that problem. It doesn’t need data to come up with formulas anymore. It can create a new algorithm that did not exist before and verify the correctness of the solution during program execution, much like how developers test and validate their code at runtime.
Hands-On vs. Hands-Off Approach
 The arrival of reasoning models such as o3 changes how developers will write code. Most of us will rely on AI-generated code. However, the question is whether we will review that code and take responsibility for it. This will lead to two distinct approaches to building software:
The arrival of reasoning models such as o3 changes how developers will write code. Most of us will rely on AI-generated code. However, the question is whether we will review that code and take responsibility for it. This will lead to two distinct approaches to building software:
Hands-On Approach
Developers will use tools like GitHub Copilot, powered by o3, to generate code. However, they will actively review, refine, and take ownership of the AI-generated output. We are already seeing examples of this with greenfield applications, but o3 is poised to make it the standard across all types of software development.
Hands-Off Approach
Users will utilize tools like ChatGPT, which leverage o3, to address their business problems. Their initial prompt will articulate the business requirements in plain English. After refining the requirements, users will interact with the chat interface for subsequent operations. Here, program synthesis occurs during the initial prompt, while program execution unfolds within the conversations. This approach can be extended to apps in the GPT Store and elsewhere using API.
Summary
With the launch of o3, it’s clear that users will soon be able to generate working code effortlessly. More concretely, well-defined libraries we use in applications, such as npm packages and open-source projects, will likely be AI-generated within a couple of years. While some developers might review and publish this code, we should assume that, in many cases, only the AI will truly understand how these libraries work. Does this mean we can trust AI the way we’ve trusted unknown open-source contributors in the past? If you extend this analogy to cancer research, if AI comes up with a solution that researchers cannot understand, should we use it to save lives or avoid it because humans don’t understand it yet? These ideological questions will shape the future. I, for one, want the hands-on approach to succeed. Developers must understand and take responsibility for the logic AI generates if they are to launch it as an application for others. If we forfeit our understanding, the reasoning in AI would bring an end to reasoning in humans. Our ability to understand the code that AI generates will decide if we are the puppeteers or puppets of AI.
Computers follow exact rules. They understand logic like "Delhi" ≠ "Chennai" or "Population of Delhi" > 30 million. However, they struggle to understand the concept of similarity (≈). For example, to us, "Delhi" ≈ "Noida" because both are part of the National Capital Region, but computers can't grasp that naturally. To make computers as intelligent as humans, we first need to teach them the concept of similarity (≈). How do we do that?
It's all about distance
 In the Tamil movie Puthumaipithan, Vadivelu plays the role of a politician who explains to journalists why places near Delhi have more political influence than Chennai. His answer? "It’s distance." He goes on to propose moving Chennai closer to Delhi to gain more influence. While this idea may seem absurd at first, it's actually similar to how AI works. AI uses 'distance' to understand how close or similar different entities are. In this post, I'll show how AI applies this concept to determine similarity between different entities like cities. First, we'll look at how Noida is closer to Delhi, then see how Chennai can be considered closer to Delhi depending on the context.
In the Tamil movie Puthumaipithan, Vadivelu plays the role of a politician who explains to journalists why places near Delhi have more political influence than Chennai. His answer? "It’s distance." He goes on to propose moving Chennai closer to Delhi to gain more influence. While this idea may seem absurd at first, it's actually similar to how AI works. AI uses 'distance' to understand how close or similar different entities are. In this post, I'll show how AI applies this concept to determine similarity between different entities like cities. First, we'll look at how Noida is closer to Delhi, then see how Chennai can be considered closer to Delhi depending on the context.
For a politician, Noida ≈ Delhi
 Let's take a politician like Vadivelu as our first example. For a politician, the closer the two cities are, the more similar they are in terms of language, culture, and voting patterns. If you provide a computer with the latitude and longitude of Delhi, Noida, and Chennai, it can calculate the distances between the cities. Based on distance, it can conclude that "Noida" is closer to "Delhi" than "Chennai." Computers excel at calculating exact distances, which helps them determine which cities are similar in this specific context. Computers use machine learning (ML) algorithms to calculate the distance between entities like cities to determine their similarity. We train these algorithms to focus only on the characteristics relevant to a specific use case—such as latitude and longitude for physical distance.
Let's take a politician like Vadivelu as our first example. For a politician, the closer the two cities are, the more similar they are in terms of language, culture, and voting patterns. If you provide a computer with the latitude and longitude of Delhi, Noida, and Chennai, it can calculate the distances between the cities. Based on distance, it can conclude that "Noida" is closer to "Delhi" than "Chennai." Computers excel at calculating exact distances, which helps them determine which cities are similar in this specific context. Computers use machine learning (ML) algorithms to calculate the distance between entities like cities to determine their similarity. We train these algorithms to focus only on the characteristics relevant to a specific use case—such as latitude and longitude for physical distance.
For an entrepreneur, Chennai ≈ Delhi
 Now, consider an entrepreneur looking to expand their business. They want to find a city similar to "Delhi." In this scenario, you would provide different characteristics like "tier" (the size of the city) and "population." This data would show that "Chennai" is more similar to "Delhi" than "Noida" because both Chennai and Delhi are tier-1 cities with similar populations. In this case, the 'distance' doesn't refer to physical proximity but rather to how similar they are in characteristics like population and city size. This ability to find similarities using machine learning helps computers perform pattern matching. This is similar to how humans do pattern recognition and represents a foundational step towards achieving human-like intelligence.
Now, consider an entrepreneur looking to expand their business. They want to find a city similar to "Delhi." In this scenario, you would provide different characteristics like "tier" (the size of the city) and "population." This data would show that "Chennai" is more similar to "Delhi" than "Noida" because both Chennai and Delhi are tier-1 cities with similar populations. In this case, the 'distance' doesn't refer to physical proximity but rather to how similar they are in characteristics like population and city size. This ability to find similarities using machine learning helps computers perform pattern matching. This is similar to how humans do pattern recognition and represents a foundational step towards achieving human-like intelligence.
Narrow AI
The characteristics such as latitude/longitude provided to an ML algorithm depend on the use case—whether it’s for a politician to compete in an election or an entrepreneur to expand their company. In both cases, calculating similarity requires a lot of data, such as knowing the details of all the cities. If you don't have enough data, the algorithm won't work correctly. This is known as the "cold start problem" in machine learning. This was what we tried to solve at our startup, Guesswork, back in 2013. By focusing on one specific use case—customer information—we could pre-train our ML model and solve the cold start problem. Hence, these models were called narrow AI.
General Purpose AI
The current AI era has given rise to a new breed of models called Large Language Models (LLMs). These models solve the cold start problem differently. They are trained on vast amounts of information available on the internet. They understand thousands of characteristics about each word, such as "Delhi" or "Chennai." Instead of using simple two-dimensional charts, LLMs represent words like "Delhi" and "Chennai" in a multidimensional space, where each dimension captures a specific characteristic of the cities. They can then calculate the distance between words in that space to understand similarities—even without specific training data.
But there is still a challenge: How do you make sure the model focuses on only certain characteristics? For example, if you’re a politician trying to find a similar city for an election, the model should focus on latitude and longitude to calculate the distance. But if you’re an entrepreneur, it should focus on tier and population. How do you do that?
Prompting: With prompting, you instruct the model in plain English to focus on the right characteristics. For example, if a politician asks the model to find a city similar to Delhi for an election, the model might consider that latitude and longitude are important because being close could influence political support. Therefore, it would suggest Noida over Chennai.
Fine-Tuning: In fine-tuning, you train the model with examples. This might look similar to ML models from the past, but it is different. Traditional ML models start with no knowledge. But, fine-tuned models already have knowledge from the internet and can focus on characteristics mentioned in the examples. In our case, it knows about the language and culture of the cities, but it will pay more attention to latitude and longitude because we emphasized them in the examples. In short, traditional ML models need a lot of examples, and prompting can be unpredictable without examples. Fine-tuning balances both and gives predictable results with fewer examples.
But LLMs can do more than just find similar cities—they can also explain why. For example, they can explain why Chennai might be better for starting a business than Noida, all in plain English. This works a bit like Google Translate. In Google Translate, you provide a fact about Delhi and ask it to translate it into another language. With LLMs, you provide a fact about Delhi and ask it to transform that fact for Chennai. This kind of transformation is called generative AI, which is used in tools like ChatGPT.
Summary
Computers follow exact rules, so we call them deterministic. But when computers understand ≈, we call them probabilistic. This is because they calculate the distance between two entities and conclude that they are “probably” similar. As long as a computer can measure how "close" two entities are, it can determine if they are similar, understand their connection, and provide meaningful answers. This simple idea of similarity (≈) was a major stepping stone for computers, enabling them to make decisions that are not just logical but also intuitive—much like humans do. AI has taken that concept and turned it into something magical—whether it's answering our questions or helping us make decisions—reshaping the world as we know it.
When you create a leave application form using Google Forms, you notice how effortless it is to add fields, one by one. However, with an AI-enabled form builder like Formfacade, the form is generated automatically as soon as you enter the title “leave application form.” This marks a fundamental shift in how products are being built. Instead of simplifying form creation on a blank canvas, products are now pre-creating forms, giving users a tailored starting point.
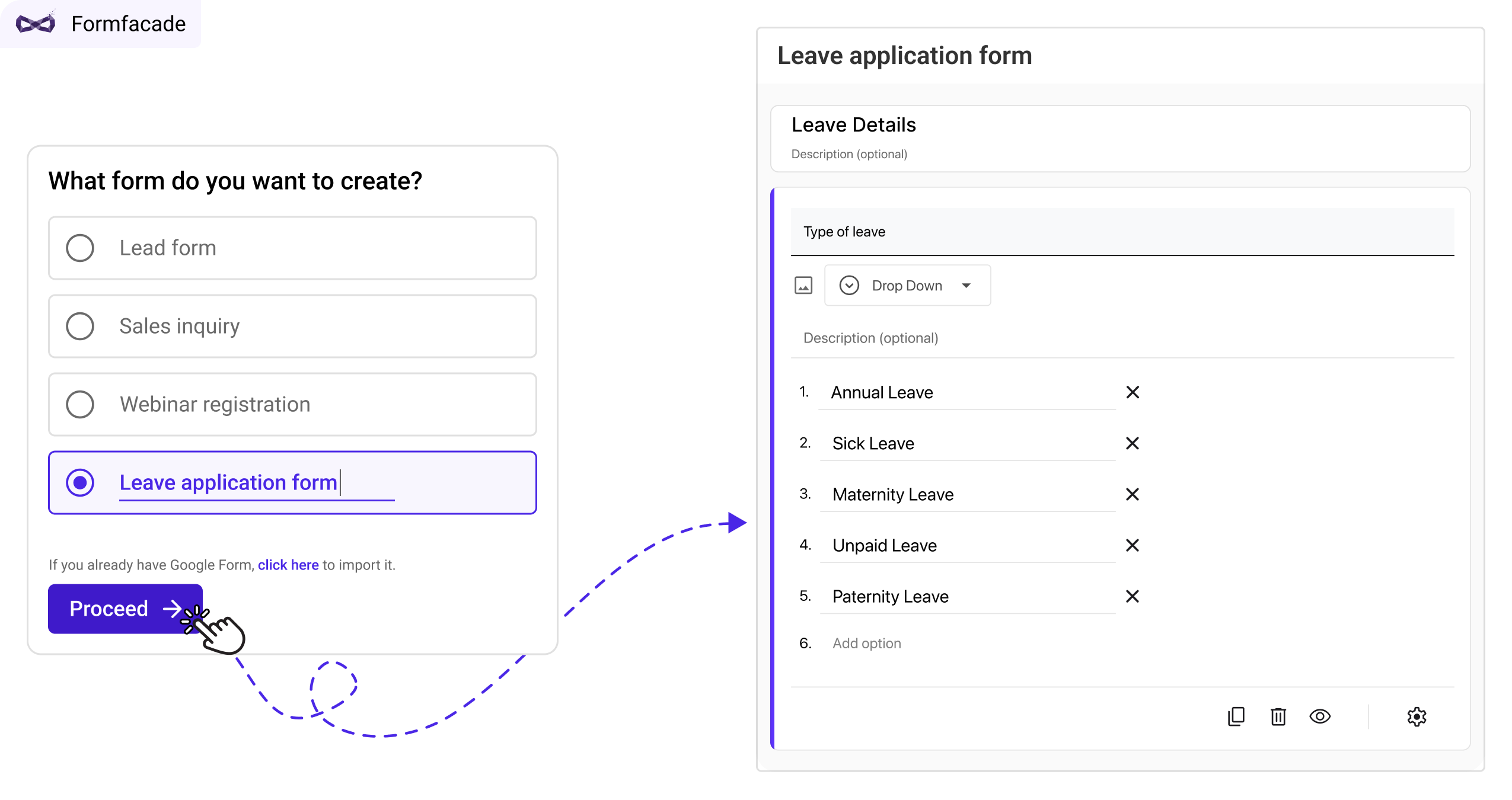
Prompting will replace templates in B2B products
In the past, products like Google Forms addressed form creation by offering a variety of templates. Due to the wide range of user needs, many of these templates were crowdsourced from users, leading to inconsistent quality and difficulty in finding the right one. In the future, products will use a handful of base templates as a “seed” for AI to generate customized templates for each user. At Formfacade, we use Promptrepo to create AI model from our pre-existing form templates. This model is used to pre-create form automatically when the user enters a form title.
This shift fundamentally changes the onboarding experience. The focus will no longer be on teaching users to add fields to a blank canvas. Instead, products will make it easy to edit pre-created forms (e.g., "Add final polish" in ChatGPT 4o with canvas). In both scenarios—form title during creation and form fields during editing—the form itself acts as the prompt, rather than relying on user-entered prompt as seen in many AI-enabled apps today. This change applies not only to form builders but also to other platforms, from Canva to WordPress. Eventually, these products will be redesigned—or replaced—by new solutions that offer pre-filled canvas ready for editing, rather than blank slates requiring manual setup.
Agents will replace integration in consumer products
While prompting helps prefill information within a single app, AI agents will work across multiple apps to prefill information. Consider planning a trip to attend a conference. Typically, you would need to interact with separate apps for booking the conference, airline tickets, and hotel accommodations. In the past, integrations were built between each of these applications to avoid reentering the same information. In an AI-enabled future, agents will work across these platforms based on a single input, dynamically building the necessary integration between user-facing apps on the fly.
AI agents will handle multiple applications behind the scenes, allowing you to interact through one interface. This seamless, cross-platform experience could unfold over multiple days, with a single app serving as the central point of your journey rather than requiring you to juggle multiple apps. The conference booking app, for instance, could become the origin of your trip, coordinating all necessary bookings. Additionally, this app could collect affiliate fees from other applications involved in the process.
Summary
Ten years ago, I explained how software was augmented with hardware in the SaaS era, leading to new wave of products like Salesforce. And, I predicted that the next wave would augment intelligence with software using AI. Specifically, AI would automate tasks—such as prefilled leads in CRM systems—that required human intelligence. Today, with the rise of generative AI, we are moving in that direction, although we may have been influenced too much by the success of ChatGPT. Instead of focusing on prefilling information, we are adding chat interfaces to all products, even when they may be unnecessary. I believe that once we refocus on solving core use cases rather than simply emulating ChatGPT's success, we will see this shift:
Prompting will redefine B2B SaaS onboarding by replacing blank canvas with tailored form or content based on minimal user input like form title. Meanwhile, AI agents will integrate multiple apps on the fly, enabling users to accomplish tasks across products from a single interface. In essence, prompting will redefine B2B products, while agents will redefine consumer products.
Remember when you emailed your manager for sick leave, and they approved it with a kind "take care"? Then one day, instead of a warm response, you got a link to a leave request form from HR. Suddenly, what used to be a human interaction turned into a cold, bureaucratic process. Why do companies do this? Why turn simple conversations into forms?
Users need chain of thought more than AI
While AI companies are building "chain of thought" into their language models, we are the ones who need it the most. Whether it's filling out a leave request form (painful) or a Y Combinator application (thoughtful), the questions in the form make us think. If we sent them through email, we wouldn't consider all the necessary details. We might say, "I'm feeling unwell, taking the next two days off," and that feels natural to us. But for the HR department, there's much more they need to know—like how many leave days you have left, whether it affects payroll, and if your manager has approved it.
Companies turn conversations into structured forms because it streamlines information gathering. Instead of HR needing to follow up for missing details, a form can capture all this information upfront, reducing delays and confusion. As we automate these processes with AI, this balance must be maintained. AI should not only convert our conversation into a leave request; it should also prompt us for missing information, similar to required fields and validations in a form.
Chain of thought in business logic
This need for structured data doesn't stop at how we provide information; it also influences how we process it. For instance, if someone has exhausted their leave balance, applying simple, deterministic rules to structured data yields better results than relying on AI models that use probabilistic logic. Deterministic logic rules are more reliable than AI that relies on probabilistic reasoning. This is especially important in regulated industries like insurance, where the step-by-step logic leading to a decision is not only preferable but mandatory.

Extending chain of thought to UI
But how do you communicate this to the user? Should AI respond like a screen reader, dictating these details step by step? Or should it show a pre-filled form, visually presenting the information all at once? The answer is clear — user interface is far more efficient than a chat response because it offers clarity and speed of comprehension. Think about ordering a cab on Uber. Instead of receiving chat updates about the cars around you, a UI that shows the cars on a map is far more efficient and clear. This is where generative AI often falls short—chatting endlessly when a well-designed interface would be more effective.
Semantic AI
At Promptrepo, we call this approach 'Semantic AI' — it's about understanding the meaning behind our words to extract structured data from conversations and presenting it in a modality that's easier for you. Semantic AI will identify key details like dates and reasons when you send an email about taking leave. It will then automatically populate the necessary fields in a leave request form for you to verify and submit. This way, AI assists in maintaining our natural communication style while ensuring all required information is captured.
![]() Once the generative AI hype settles, we believe the true power of AI will lie in extracting structured data rather than generating a "word salad." As AI continues to evolve, we'll see a shift in its architecture. While generative AI relies on probabilistic logic and chat-based interaction, Semantic AI will focus on structured data and deterministic logic. Structured data isn't just a business need for HR to generate reports; it also helps us understand and feel informed about the consequences of our requests (such as unpaid leave, price change), making interactions with AI meaningful and effective.
Once the generative AI hype settles, we believe the true power of AI will lie in extracting structured data rather than generating a "word salad." As AI continues to evolve, we'll see a shift in its architecture. While generative AI relies on probabilistic logic and chat-based interaction, Semantic AI will focus on structured data and deterministic logic. Structured data isn't just a business need for HR to generate reports; it also helps us understand and feel informed about the consequences of our requests (such as unpaid leave, price change), making interactions with AI meaningful and effective.
In the 2018 World Chess Championship, Magnus Carlsen and Fabiano Caruana's game ended in a draw despite Caruana's material advantage. Stockfish, the powerful chess engine, revealed a stunning missed opportunity: a forced checkmate in 35 moves.
Stockfish's analysis suggested unconventional moves, like trapping the Knight on the edge of the board—moves no human would consider. This showcased Stockfish's ability to see far beyond human intuition, highlighting the power of AI in uncovering deep, hidden strategies in chess, even outwitting the world's best players.
Stockfish is a narrow AI with a rating estimated to be over 3500. This is significantly higher than Magnus Carlsen’s rating of 2882. Within its specific domain, Stockfish demonstrates superintelligent behavior. This trend is likely to happen in other fields, such as programming and customer support, where AI could surpass the world's best experts. If we extrapolate this trend, we can predict three outcomes:
1. AI will enhance, not replace human expertise
To improve their game, players use Stockfish to analyze their chess moves. This has contributed to the growth of top chess players, since its launch in 2008:
Decade | Grandmasters | International Masters | FIDE Masters | Candidate Masters |
|---|---|---|---|---|
1970s | 82 | 200 | 500 | 500 |
1980s | 300 | 400 | 1000 | 1000 |
1990s | 600 | 800 | 2000 | 2000 |
2000s | 1000 | 1500 | 3500 | 3000 |
2010s | 1500 | 2000 | 5000 | 4000 |
2020s | 1722 | 2400 | 6000 | 5000 |
Similarly, top performers in different fields will increase, not decrease with AI. AI will teach us to be superhumans. On platforms like Chess.com, you can play for free but pay to improve your game using Stockfish. Similarly, future apps might be free, but you might pay for AI-driven learning. Edtech might not be a separate vertical; it could be the premium version in all verticals.
2. AI automation might be considered cheating
Using Stockfish in competition is considered cheating. In the 2022 Sinquefield Cup, World Chess Champion Magnus Carlsen resigned, suspecting his opponent, Hans Niemann, of using Stockfish. This caused a stir in the chess world, raising concerns about the impact of technology. The same might happen with AI assistants. Using AI to learn might be the norm, but delegating your work to AI could be frowned upon like cheating. AI would be a teacher, not a proxy who writes exam for you. If you are rebranding your product as AI, you might want to hold your horses. Investors might like it, but customers may not.
Note: For people who think customers care only about the output, this didn't happen in chess. We don't watch Stockfish vs. Magnus Carlsen games. Magnus Carlsen is the star we celebrate, not Stockfish.
3. Super intelligence could be deterministic
In the endgame, Stockfish acts like a deterministic algorithm, using precomputed tablebases to make perfect moves with absolute certainty. This capability outstrips even Magnus Carlsen, as Stockfish can foresee and execute a flawless 35-move checkmate sequence that no human could match. This combination of a probabilistic middle game and a deterministic endgame makes it unbeatable.
AI will hit a plateau once LLMs have read all available text and reach the IQ of top experts in various fields. However, just as Stockfish has surpassed Carlsen's rating of 2882 through the use of deterministic algorithms, artificial superintelligence could achieve unprecedented levels of capability by combining the adaptability of probabilistic LLMs with the precision of deterministic systems. Given that deterministic systems have a 50-year head start over probabilistic LLMs, this hybrid approach could excel at both nuanced tasks and well-defined problems, ultimately surpassing human capabilities across many domains.
Conclusion
Ten years ago, I predicted the impact of AI on CRM and other business sectors. Most of these predictions have come true, except for the widespread combination of rule engines with machine learning. If chess is a leading indicator, I still believe that superintelligence will combine deterministic algorithms and probabilistic LLMs, excelling at both structured and nuanced tasks. Its adoption in chess not only showcases technological prowess but also provides a blueprint for thriving with superintelligence instead of being scared about it.
Code Generation AI is all the rage these days. But is generating code for programming languages like JavaScript and Python the right path to take? I think not. I think we should be generating code for declarative languages like Excel or SQL.
What's the difference, you ask?
In declarative languages, you express what your intention is. For example, in Excel, you can use SUM() to add all the line items and calculate the order amount. If the quantity of a line item changes, it will automatically recalculate the line item amount and then invoke SUM() to recalculate the order amount. But in imperative languages like JavaScript or Python, you instruct the computer on how to calculate the order amount. You would implement a function to add the line items as the order amount. Anytime the quantity of a line item changes, it is your job to call the function and recalculate the order amount.
Why is this important?
If you are asking AI to generate code for your requirements, you are essentially expressing your intent. So, expressing it in a declarative language seems natural. This will help the person who gave the requirement to understand the code generated by the AI. On the other hand, generating code for a programming language seems like the worst form of leaky abstraction. "Leaky abstraction" describes a scenario where attempts to simplify a system end up requiring users to understand its underlying complexities to troubleshoot it. Code generation can automate the creation process. But, the resulting code can be a puzzle even to a skilled developer who is debugging it. The person who gave the requirement will most likely not understand any of it.
So, why do AI companies generate code like this?
I guess it comes down to the availability of training data for AI. There are a lot of open-source projects in JavaScript or Python, so it is easy to train AI with it. But open-source projects in Excel are almost non-existent. So, the unavailability of training data might be the primary reason behind the direction these code generation AI companies are taking. At Neartail, we are taking a middle road. We have created a declarative language using JavaScript syntax so that we could train the AI as well as make it understandable to business owners. Will other AI companies realize the perils of leaky abstraction and change its course? Only time will tell.